Hi Friends,
I had started the SQL Server index internal series sometime back. The first part is here;
Apologies for making it late on Part 2 – this part is more about some food for thought in SQL Server index internals. So here is the question:
In AdventureWorks database, there is a table called Person.Contact and there is a clustered index on COntactID. So here are the scenarios:
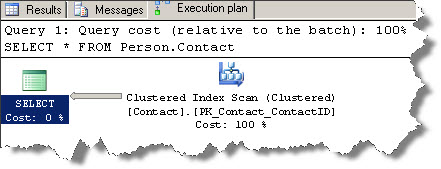
When you issue out the following query, the optimizer rightly does a clustered index scan:
SELECT* FROM Person.Contact
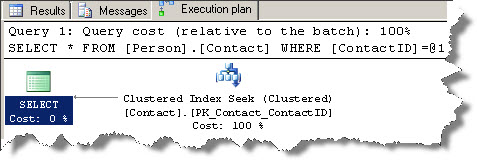
When you issue out the following query, the optimizer rightly does a clustered index seek. The output gives you one record, which means SQL Server has done one seek.
SELECT* FROM Person.Contact where ContactID = 1
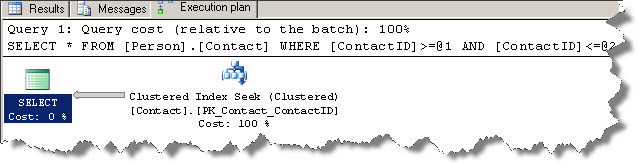
But when you issue out the following query, it seeks again. The output returns 17995 records. Does it mean that SQL Server is seeking 17995 times???
SELECT* FROM Person.Contact where ContactID BETWEEN 1 AND 18000
I hope the scenario is clear. I am looking for answers from all of you. Let me know what you think. Why is the optimizer SEEKING instead of scanning, as you know, in this case, scanning could be faster. Awaiting your responses !
Hi Amit,
Interesting ask. To keep my answer short, I’d say (it loud) that Index seek is a confusing term. It is either a seek or a seek over a range scan as it depends upon the predicate specified. For example, in this case when you specify “where ContactID BETWEEN 1 AND 18000” the clustered index PK_Contact_ContactID is actually doing a seek staring from the root but at the leaf level it scan for a range which satisfies ContactID>1 and ContactID<18000 in an orderly fashion.
If you look at the XML plan (or properties of the CI seek operator in graphical plan) you will see the same
May be the stastics are out of date & query analyzer thought it is better to have index seek than index scan.
or
By using between keyword it is searching between two predicate’s as shown in execution plan & query analyzer is unaware of how many values its going to return.
Since, ContactID is the key in the Clustered Index, the optmizer seeks the 1st ocurrence of ContactID (1).
Since the Index/table is physically ordered on ContactID, All ContactID BETWEEN 1 AND 18000 wiil be returned by seeking the last position of the
ordered range. Almost as when one uses low level file operations with (FOPEN, FSEEK, FREAD etc). Let’s say we had a non clustered index based on lastname
and firstname. If we were to look for (“john Smith”). The first thing the optmizer would do is an index seek to position itself in the first ocurrence of “Smith”. Then an Index Scan within the “Smith” dataset that woilukd be ordered by name, to then look for “John”.
Hello,
When whole table data is searched on or say no where clause is applied in your select statement SQL server scans whole table to fetch the results.
When there is a where clause or something like range is given to select result from the table it will always perform a cluster seek…
So the secret lies in Range in where clause.
This is because Optimizer is beliving that it does not have to scan the entire table and there is an available index on ContactID. It therefore uses this Index along with partial scan. Hope this answers…Thanks