Hi Friends,
In my previous blog post Part 6 on this series we saw how SQL Server execution plan changes when we use ORDER BY clause in SELECT statements. Today, we will have a look at execution plan when we introduce GROUP BY clause.
EXECUTION Plan with GROUP BY
We will query Person.Address table to retrieve total count for each City;
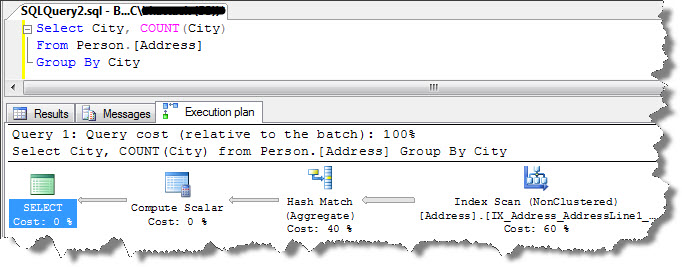
There is no WHERE clause in query hence execution began with an Index Scan. These rows are then had to be aggregated in order to perform COUNT operation. In order to count each row for different cities, query optimizer performed a HASH MATCH. This hash match is a bit different from the one that I discussed on Part 4 as when you look underneath, you can see a word ‘aggregate’ in parentheses. A Hash Match join with aggregate causes a temporary hash table in memory in order to count number of rows that are matched by GROUP BY column, here in our case it is CITY. As soon as results are aggregated the results sent back to us. They can prove to be expensive operations. You can minimize this to restrict query results using appropriate checks in WHERE clause.
Let us now check, what happens when query results are filtered using HAVING clause;
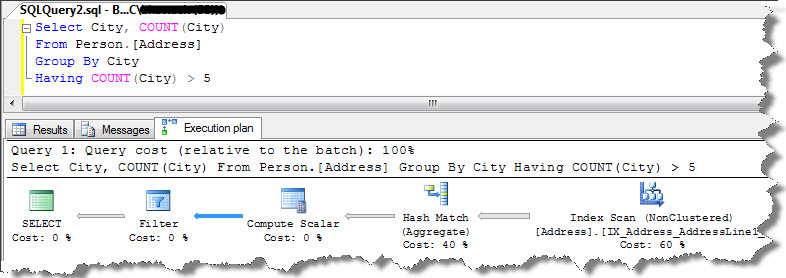
By adding HAVING clause, FILTER operator is added to the plan to limit the output i.e. City count that are greater than 5. Interesting thing to observe here is HAVING clause isn’t applied until aggregation operation completed. We can see that, actual number of rows in HASH MATCH is 575 and in FILTER it is 243.
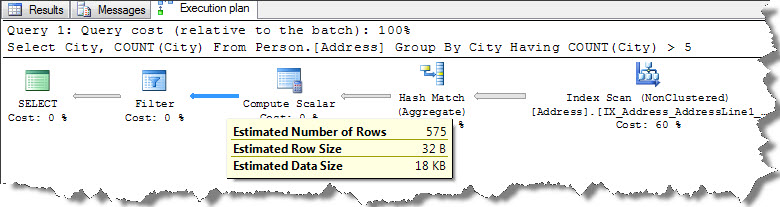
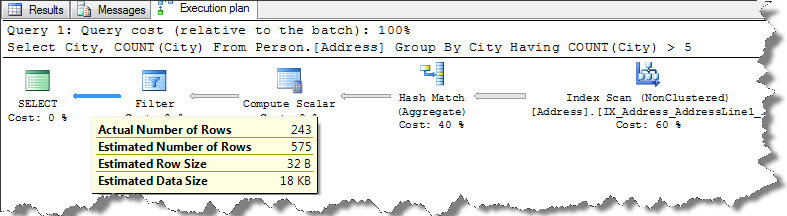
HAVING clause did not come into play until aggregation, it did reduce number of records to be returned but it adds to the resources that are required to produce query output. So, as discussed earlier today, it is always better to check for the possibilities if we can put appropriate checks in WHERE clause to limit rows to be aggregated.
See you soon guys with next one on this series!
Regards
Kanchan Bhattacharyya
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook