Hello Geeks and welcome to the Day 70 of the long series of One DMV a day. In this series of blogs I will be exploring and explaining the most useful DMVs in SQL Server. As we go ahead in this series we will also talk about the usage, linking between DMVs and some scenarios where these DMVs will be helpful while you are using SQL Server. For the complete list in the series please click here.
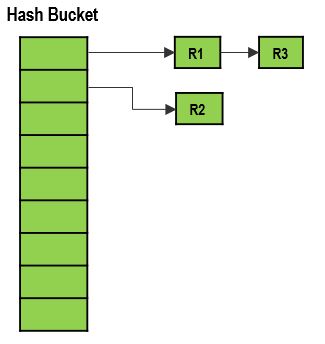
Today I will be covering sys.dm_db_xtp_hash_index_stats. The data is stored in Memory Optimized tables uses the hash bucket concept. The index value is hashed using a hashing function and put in a hash bucket. As the index value duplicates to same hash value it builds up a linked list in the bucket. The structure looks something like the below.
Sys.dm_db_xtp_hash_index_stats shows the columns which will provide stats of this hash index.
When the number of buckets is low then more indexes are hashed to same bucket. This increases the average and maximum length of the chain. You may see performance problems if this is too high. The columns which measure these values are empty_bucket_count, avg_chain_length and max_chain_length.
One more issue that can be identified using sys.dm_db_xtp_hash_index_stats is duplicate index key or a skew in key values. A skew is a term we hear more often. So let me put it in easier English. Imagine a table where you created index based on state id in India. As most of the IT population is spread across five states in India, all these five state Ids are heavily used. This means bigger chain for these buckets and most of other buckets are not even used. This is skew on those buckets. The dictionary meaning is crooked. 🙂
To identify this in sys.dm_db_xtp_hash_index_stats you will observe high value for max_chain_length and empty_bucket_count relative to avg_chain_length. This is how an output for a good hash table looks like from sys.dm_db_xtp_hash_index_stats.
SELECT OBJECT_NAME(object_id) AS name, index_id, total_bucket_count, empty_bucket_count, avg_chain_length, max_chain_length FROM sys.dm_db_xtp_hash_index_stats
![]()
Tomorrow I will be covering another In-Memory optimized tables related DMV. So stay tuned. Till then
Happy Learning,
Manu
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook |
Follow me on Twitter | Follow me on FaceBook