I was working on removing duplicate indexes from a table. Before removing an index usually I check whether that index is used by any query or not, is there any index hint is used, looking at index usage statistics and many other factors.
If you search in web you will get many ways to identify duplicate indexes and to remove them. . I refer Kimberly Tripp to find duplicate index.
So Here I’m not going to tell, how to find duplicate indexes. Here I’ll reveal a scenario where non-clustered index seek is better than clustered index seek and how you can find the reason for this?
Demo:
Create Database DEMO
Go
CREATE TABLE [dbo].[MyTable](
[Key1] [char](4) NOT NULL,
[Key2] [int] NOT NULL,
[id] [int] NULL,
[Key3] [bit] NOT NULL,
[DeleteIndicator] [bit] NULL,
[createdby] [varchar](50) NOT NULL,
[createtimestamp] [datetime] NOT NULL,
[modifiedby] [varchar](50) NOT NULL,
[modifytimestamp] [datetime] NOT NULL
CONSTRAINT [pk_MyTableIndex] PRIMARY KEY CLUSTERED
(
[Key1] ASC,
[Key2] ASC,
[Key3] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY])
GO
CREATE NONCLUSTERED INDEX [INDX_Key1_Key2_Key3] ON [dbo].[MyTable]
(
[Key1] ASC,
[Key2] ASC,
[Key3] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]
GO
Above script will create a database and table Mytable under DEMO database. Then it will create one index [INDX_Key1_Key2_Key3] on column key1, key2, key3.
Now we have two indexes one is clustered and one is non-clustered and both are created on same columns. Below query will return all index detail created on table MyTable.
select * from sys.indexes where object_id = OBJECT_ID('MyTable')
Below result showing, there are two indexes on table ‘MyTable’.

Let’s populate some records in table MyTable.
CREATE TABLE Numbers(num int identity ) GO INSERT Numbers default values GO 10000 INSERT INTO [MyTable] ([Key1] , [Key2] , [id] , [Key3], [DeleteIndicator] , [createdby] , [createtimestamp], [modifiedby] , [modifytimestamp]) SELECT top 700 'ABCD', num,NULL,0,0,'SQLServer',GETDATE(),'SQLServer',GETDATE() FROM Numbers INSERT INTO [MyTable] ([Key1] , [Key2] , [id] , [Key3], [DeleteIndicator] , [createdby] , [createtimestamp], [modifiedby] , [modifytimestamp]) SELECT top 300 'DEFG', num,NULL,0,0,'SQLServer',GETDATE(),'SQLServer',GETDATE() FROM Numbers
Now run the below query and include actual execution plan.
SELECT key1 FROM MyTable WHERE Key1='ABCD'
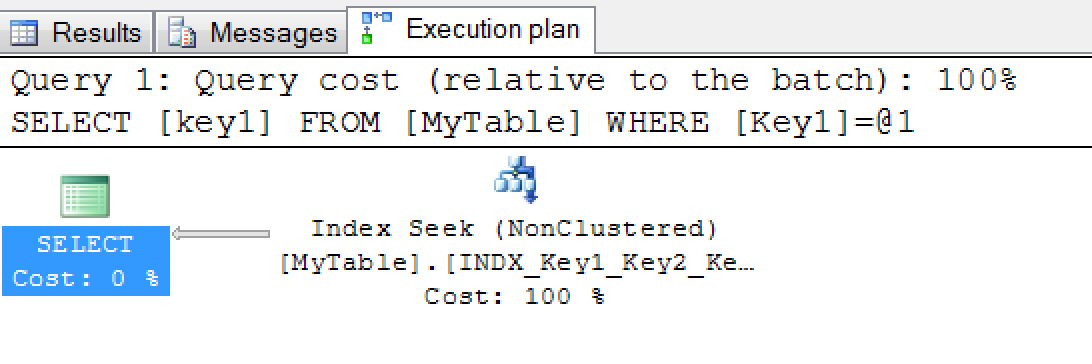
For the above query, optimizer chooses non-clustered index seek over clustered index seek.
At this stage I feel why didn’t it use clustered Index seek? As the Colum and predicate both is part of clustered index key. To know why optimizer use Non Clustered Index seek over Clustered index seek I compare existing query with same query applying clustered index key hint.
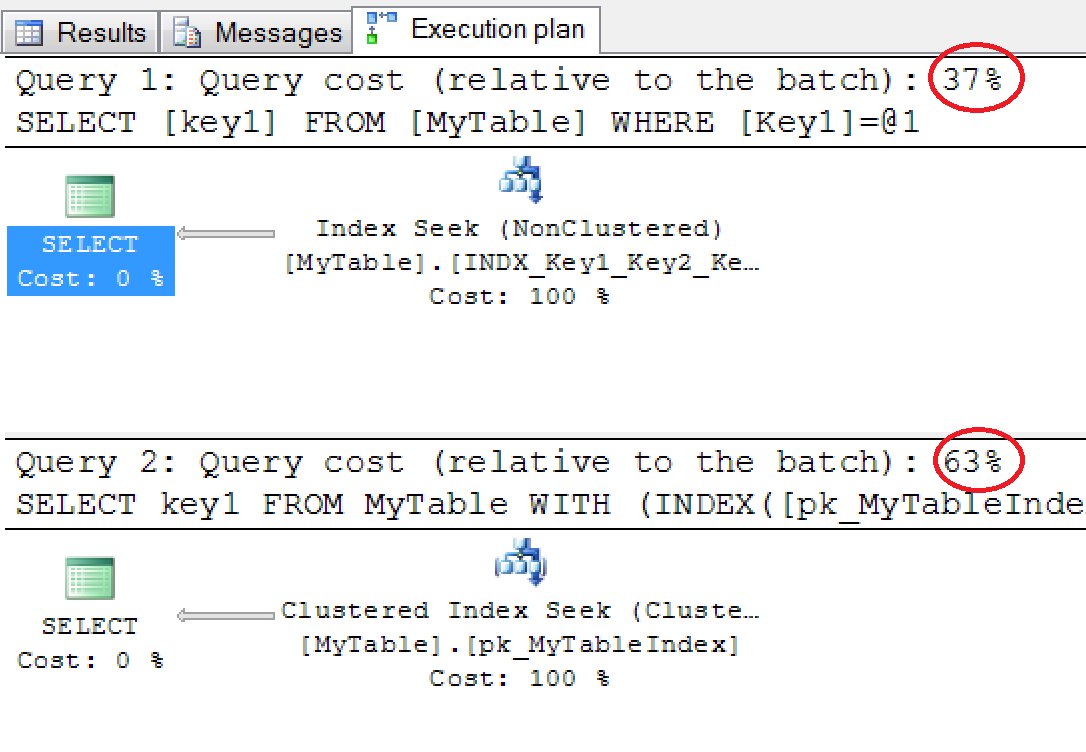
The execution cost is more if it uses clustered index seek so it uses non clustered index seek over clustered index seek.
Why Clustered index seek is more costly?
To know the reason, I compare both operator details and found in case of clustered index seek the Estimated I/O cost is more.
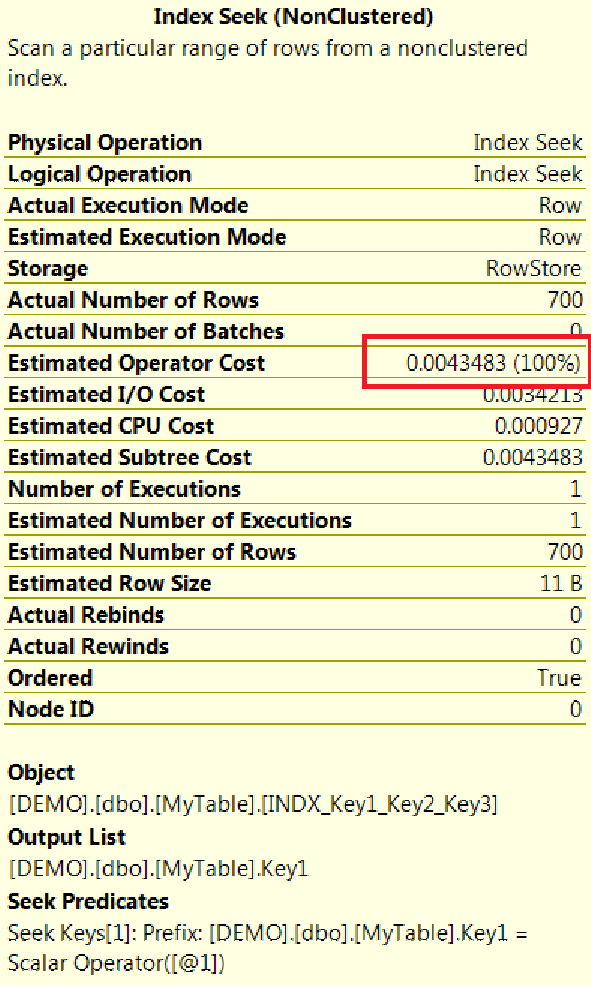
Why Estimated I/O is more in case of clustered index seek?
To answer to this question let’s collect statistics IO for both the queries. See below the logical reads is more in case of clustered index seek i.e.8 logical reads where as non-clustered index has only 3 logical reads.
SET STATISTICS IO ON SELECT key1 FROM MyTable WHERE Key1='ABCD' SELECT key1 FROM MyTable WITH (INDEX([pk_MyTable])) WHERE Key1='ABCD'

Why Logical reads is more in case of clustered index seek?
It happened because in clustered index, the leaf level stored actual data row and non-clustered index contain only index key at leaf level and Clustered index row size at leaf level is greater in size as compared to non-clustered index row at leaf level. In result non-clustered index leaf level can accommodate more rows per data page.
In our query we are fetching column key1 which is part of index key for both clustered index and non-clustered index but here the optimizer choose non-clustered index seek because it look in to less number of pages.
How to find number of pages used by an index?
First find out index id of your index.
select index_id,name,type_desc from sys.indexes where object_id=OBJECT_ID('MyTable')
Pass index id to function sys.dm_db_index_physical_stats to fetch all index details.
Pass index id to function sys.dm_db_index_physical_stats to fetch all index details. Here we’ll find details for index_id 1 and 2.

We can see here in case of clustered index for 1000 records it required 8 pages as the record size is 61 bytes whereas the same 1000 records required only 2 pages in case of non-clustered index.
Both index seems duplicate but they are not duplicate because columns in leaf level are different.
I hope this blog will help you all to understand why Clustered index seek is not always good.