In today’s blog, we will be diving into yet another topic from the SQL Server Indexes, Clustered Index Seek (Range Scan).
Seek and Scan are the most used terminologies when it comes to data access methods by SQL Server. And also, there is a never-ending misconception around which method is better over another. Well, it all depends. Depends on the query. SQL Server will choose the method best for the given query.
Before we start, a quick note on the index internals.
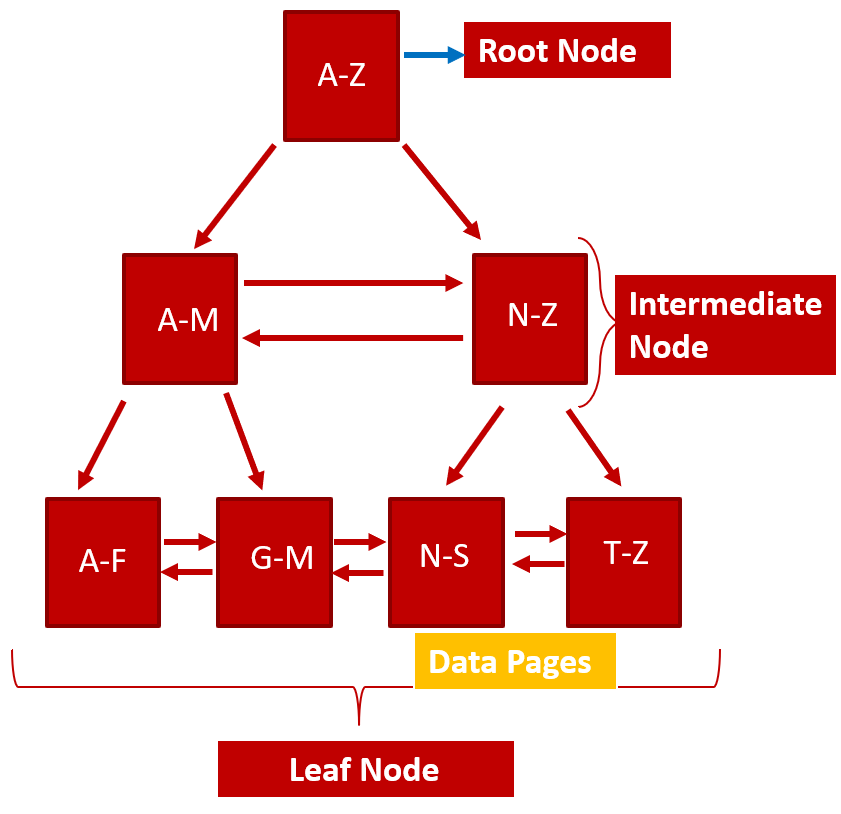
When an index is created, SQL Server internally builds a B-tree structure. There is a root node, followed by some intermediate level nodes and finally a leaf node. When SQL Server is scanning a clustered index, it is scanning all pages at the leaf level node leading to maximum I/O. Seek on the other hand looks for a particular set of data and traverses the B-Tree structure, moving from the root page to the leaf level.
It is important to remember that while dealing with indexes involving seek & scan, the number of pages involved is a critical factor. In this blog, we will look into an instance when Clustered Index Seek can be misleading. This is where ‘Range Scan’ comes into play.
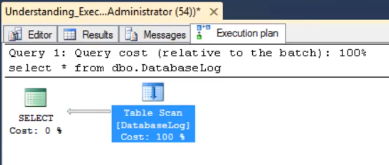
We are using AdventureWorks database for the purposes of this demo. And then enable the STATISTICS IO and Actual Execution Plan before running a SELECT statement that reads all the data from the DatabaseLog table.
USE AdventureWorks GO SET STATISTICS IO ON -- Enable Actual Execution Plan SELECT * FROM dbo.Databaselog
The execution plan shows a Table Scan, since this table is a heap (no clustered index on the table). So, the data pages are not guaranteed to be in order. It is important to note that clustered index scan and table scan essentially mean the same thing.
Next, let’s read the data from a table that has clustered index
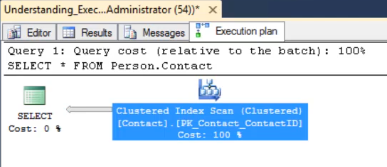
SELECT * FROM Person.Person
The Execution Plan confirms that a Clustered Index Scan is taking place.
The Messages tab displays a total of 572 logical reads. This value is crucial for performance evaluation.

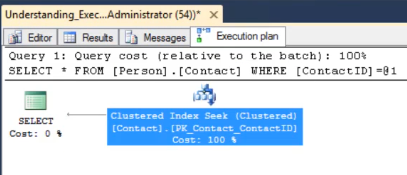
Next, a ‘seek’ operation is performed on this clustered index when we run the previous SELECT query with a WHERE predicate which returns all entries with a ContactID value of 1.
SELECT * FROM Person.Person WHERE ContactID = 1
The execution plan confirms that a Clustered Index Seek operation is taking place.
In the Messages tab, the value for logical reads is only 2, stating that only two pages were touched, the root page and the respective leaf level page where the ContactID 1 resides.
In case of a predicate containing a relational operator such as ‘greater than’ or ‘less than’, clustered index seek can prove to be misleading.
Let’s do a minor change to the predicate like below.
SELECT * FROM Person.Person WHERE ContactID > 1
Most of you would expect a scan to take place since the predicate has a ‘greater than’ operator, but the execution plan shows a Clustered Index Seek.
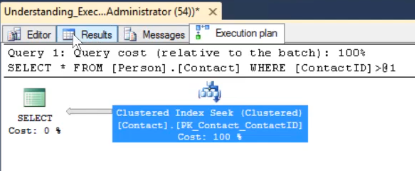
In the Messages tab, the number of logical reads shows 572, proving that the scan was performed nonetheless. It is not about which is the better of the two, but instead, comes down to the amount of I/O taking place in the background.
This background process can be termed as Range Scan. There is a Clustered Index on ContactID which is a part of the predicate that is locating the record having an ID of 1. Because the data is sorted in the order of ContactID column, SQL Server seeks to value 1 and from there on, proceed to scan the rest of the data and hence termed Range Scan.
Unfortunately, the iterator in our case is not very intuitive and hence does not inform us about the Range Scan that is taking place in the background.