Hi Geeks,
I hope you liked yesterday’s post SQL Server Merge Join operator Part1. This operator requires an equality operator and inputs sorted in join predicate. In our example from yesterday, the join predicate has an equality operator and is using SalesOrderID column which are clustered indexes in respective tables and is sorted by SalesOrderID as it is the clustering key.
As inputs are sorted, merge join reads reads a row simultaneously from each of its inputs and compares them. If the row matches, they are returned and is not the smaller value is discarded since both inputs are sorted. This process continues until one of the tables is completed. Cost of this operator is the sum of both the inputs.
In case inputs are not sorted, the query optimizer may choose a different operator. As an example, following query will use a nested loop join.
USE [AdventureWorks2012] SELECT EMP.BusinessEntityID FROM HumanResources.Employee EMP INNER JOIN Sales.SalesPerson AS SLS ON EMP.BusinessEntityID = SLS.BusinessEntityID
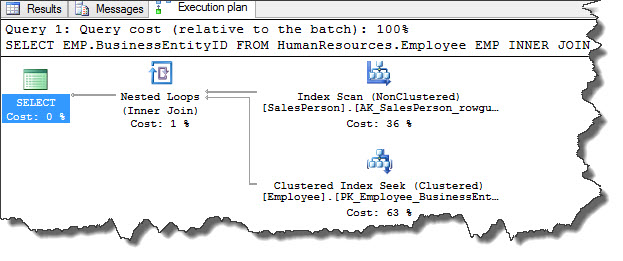
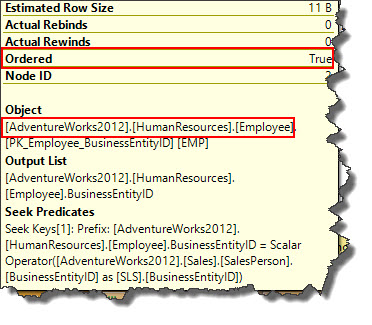
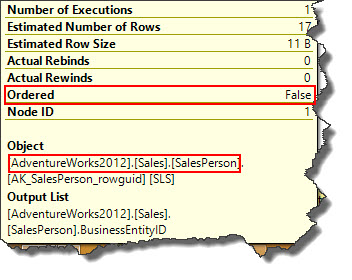
In the example, Employee table is sorted on BusinessEntityID column whereas but not on Sales table which can be verified from ToolTip and hence query optimizer chosen nested loop join and not merge join operator.
Query optimizer is most likely to choose this operator for medium to large inputs and there is an equality operator on the predicate which are sorted on both the inputs.
That’s it for today, see you tomorrow.
Happy learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook