Hello Geeks and welcome to the Day 7 of the long series of One DMV a day. In this series of blogs I will be exploring and explaining the most useful DMVs in SQL Server. As we go ahead in this series we will also talk about the usage, linking between DMVs and some scenarios where these DMVs will be helpful while you are using SQL Server. For the complete list in the series please click here.
One of the most important IO related DMVs is sys.dm_io_virtual_file_stats. This is a Dynamic Management Function which returns very useful information and as most of other stats DMVs provides the cumulative data. Today I will explain what information this DMV gives and a simple query that you can use in combination with the yesterday’s DMV, sys.dm_io_pending_io_requests.
So let me start with explaining different columns in sys.dm_io_virtual_file_stats. There are two types of operations on files viz. reads and writes. So the information collected in this DMV are no of reads/writes, no of bytes read/write, wait times for reads/writes/both to complete. Simple but valuable information when you are troubleshooting IO related issues.
As sys.dm_io_virtual_file_stats is a function is accepts two parameters, database_id and file_id. So it can get you all the information of any file in any database. There are many use cases of his DMV and I am going to keep it simple while showing its usage. I will collect the DMV data before and after running a select on a big table and we will see the stats increase for read related counter.
SELECT database_id, file_id, num_of_reads, num_of_bytes_read, io_stall_read_ms, io_stall FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) GO SELECT * FROM employee GO SELECT database_id, file_id, num_of_reads, num_of_bytes_read, io_stall_read_ms, io_stall FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL)
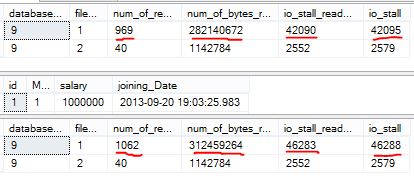
From the above results you can observe that my select statement on employee table has done reads. The difference from first result and last result of sys.dm_io_virtual_file_stats is the actual reads done by the statement. If you are seeing IO issues live on your environment and want to get the sense of which file is hitting more IO you can use below query to run with a gap of 1 minute and get the difference to troubleshoot IO related issues.
SELECT * FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) ivfs INNER JOIN sys.dm_io_pending_io_requests ipir ON ipir.io_handle = ivfs.file_handle
Tomorrow I will be covering another DMV. So, stay tuned. Till then
Happy Learning,
Manu
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook |
Follow me on Twitter | Follow me on FaceBook
good information, thanks…
Hi Manohar,
What needs to be done to reduce the size of virtual size stats? I only know that increasing the auto grow size may reduce the VLF counts. Am i rite and anything more needs to be done to reduce vlf counts.
There are two different things in your question. Virtual file stats is the statistics of the operations heppening on the files. VLFs are a different concept related to log file. And in the second case you are partially right. Ideally you should be creating the log size with the size equal to its maximum usage. This can only be achieved with multiple regressive load tests. If you know your log file will grow to 10 GB and it grows from 1 GB with 100 MB growth it will create more VLFs. So create the log file directly with 10 GB size to avoid more VLFs and log file fragmentation.
Regards,
Manu
Thanks for clarifying the doubts.