Hi Friends,
Today, I am going to show you Nested Loop Join Internals in terms of performance.
Generally, we write a query in SSMS and then submit it to SQL Server for execution. In the query, there may be join conditions like an inner join, outer join, self join, etc. all these are the logical joins because we use these in our TSQL logic. When we submit the query for execution, then SQL Server prepares an execution plan for the processing of that query. In the plan SQL Server converts the logical joins (which we wrote in the query) to physical joins like nested join, merge join, hash join, etc. Here I’ll talk about one of that physical join: Nested join.
What nested join is and how it works?
This is a physical join which takes a single row from its one of the join input (outer input table) and scans or seek the other input table (inner input table) for that join condition column. This process continues until it process all the rows from the outer input table.
You can think it like two loops – one as outer and another as inner loop. So for each row from the outer loop, the inner loop will execute to match the join condition. Let me show you with an example:
Select SOD.UnitPrice, SOH.DueDate, SOH.OrderDate from [Sales].[SalesOrderDetail] SOD join [Sales].[SalesOrderHeader] SOH on sod.SalesOrderID=SOH.SalesOrderID Where SOH.OrderDate between '2011-07-01' AND '2011-07-31' GO
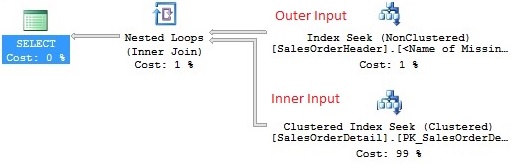
From the above execution plan,you can see there is one outer table and one inner table. If you will right click on operators and check the properties, then you will find out the number of executions for each operator. In the image below I have added properties of all the three operators.
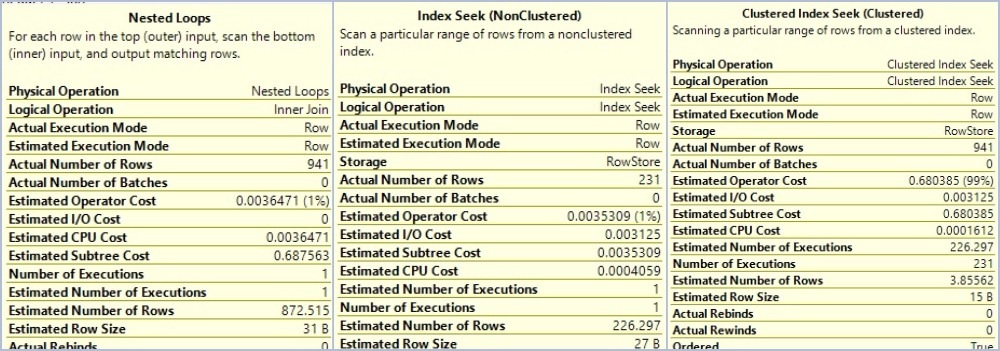
From the above two images, you can see:
- Non Clustered Index seek occurs for the outer table.
- Clustered Index seek occurs for the inner table.
The important thing to notice here is, the actual number of executions.
- For outer table = 1
- For inner table = 231
Here clustered index seek operation occurs 231 times on the inner table, this number equals to the actual number of rows in the outer table. Which clearly shows that CI seek occurs at the inner table for each row from outer table.
Generally, SQL Server selects an outer table which has less number of rows. This selection is actually based on the statistics, i.e. Estimated number of rows. The reason behind this selection is the number of iterations. Inner table operator execution will be equal to the number of rows in the outer table.
In the above example:
- Actual Number of rows in outer input: 231
- Actual Number of rows in inner input: 941
If your statistics are not updated or not correct, then you can see some performance issues. You can imagine the situation by reversing the inner and outer input. Then numbers of inner iterations will be 941 instead of 231.
HAPPY LEARNING!
Regards:
Prince Kumar Rastogi
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook
Follow Prince Rastogi on Twitter | Follow Prince Rastogi on FaceBook
Good one Prince
Thank you!
good
Is loop joining if fast