Dear Friends,
Few months back it was one of those Sunday afternoons when you really want to spend some time doing nothing more than sit and relax when my phone rang up. It was one of my junior colleagues with whom I worked years back. I realized he is bit anxious but hesitant to tell actual reason for reaching me. Anyway, after few minutes of initial talks he finally disclosed that he is in office and in one of his environments SQL Server service pack upgrade is failing on SQL Server 2008 R2 clustered instance.
Ok, he did mention that MSI/MSP checks are clean, Cluster failover worked perfectly, SQL resources found to be fine pre/post failover and failback and quite confident that everything is in place so patching should go fine.
Realizing that I cannot ask him to share his desktop to have a look into the respective server I requested him if it is possible for him to share Detail.txt file so that I could at-least have a look and understand. He agreed to it did sent file to me. When I looked into the file I found it contains cluster verification error (see below);
2013-08-25 12:50:58 Slp: Rule ‘Cluster_IsOnlineIfClustered’ detection result: Is Cluster Online Results = True; Is Cluster Verfication complete = False; Verfication Has Warnings = True; Verification Has Errors = True; on Machine XXXXXXX
Error: Action “Microsoft.SqlServer.Configuration.SetupExtension.ValidateFeatureSettingsAction” threw an exception during execution.
2013-08-25 12:51:24 Slp: Microsoft.SqlServer.Setup.Chainer.Workflow.ActionExecutionException: The cluster resource is not available. (Exception from HRESULT: 0x8007138E) —> System.Runtime.InteropServices.COMException (0x8007138E): The cluster resource is not available.
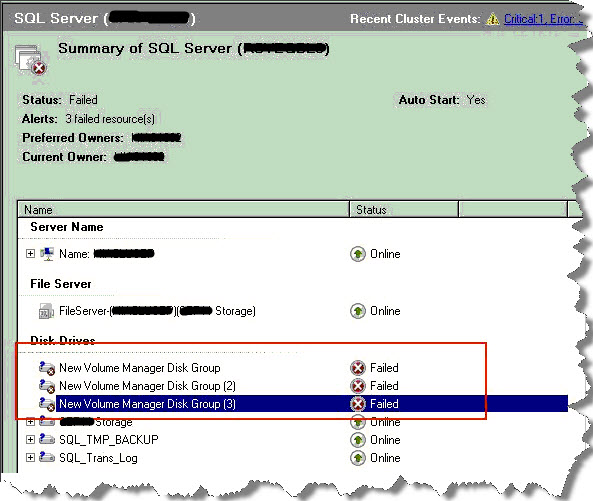
Question was; when all resources are online i.e. none of them in failed state then from where did this error message come from? To narrow down the issue, I asked my colleague if it is feasible to reboot the nodes one by one and then check if any resource fails to come online. As they were in change window he decided they are going to reboot individual nodes.
Once done; I got to know 3 disk group resources failed to come online, that were added recently. I thought before my colleague reaches storage team worth to check if they can be brought online. Yes, when tried they did come online. Time for a second reboot to find out if failure was intermittent one or persistent. No luck, second reboot also reported all 3 disk groups in failed state. Now, it was time to involve storage team which revealed there were issues with IO path and as a result on every reboot added disks were being removed resulting failures. This was finally fixed by storage team and patching went successful. My friend actually missed to check out cluster logs/event logs and of course SQL logs to get to the reason of failure.
I believe prior patching we should check for if cluster validation check is clean, any suspicious messages in event logs and FIX them at first place. Not to forget rebooting individual nodes prior patching can prove to be very useful (as observed here) though I do not want to be generic as may not apply in all environments.
Leave a comment if you have similar experience and underlying reason.
Regards
Kanchan Bhattacharyya
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook
Thanks for sharing it very valuable in cases when one is stuck in pack upgrades in clustered environment..