Hi Geeks,
Sequence project operator adds columns in order to perform computations over an ordered set and divides the input set into segments based on the value of one or more columns. This is both a physical and logical operator.
Consider following query that assigns consecutive rank to each row of a partition in other words group of records that are partitioned by the Color column and ordered by ProductNumber column. If more than one column happen to have same value for ProductNumber column, they get the same rank.
USE [AdventureWorks2012] SELECT DENSE_RANK() OVER ( PARTITION BY Product.Color ORDER BY Product.ProductNumber) AS [Rank], Product.Name, Product.Color,Product.ProductNumber,Product.SafetyStockLevel,Product.ModifiedDate FROM Production.Product
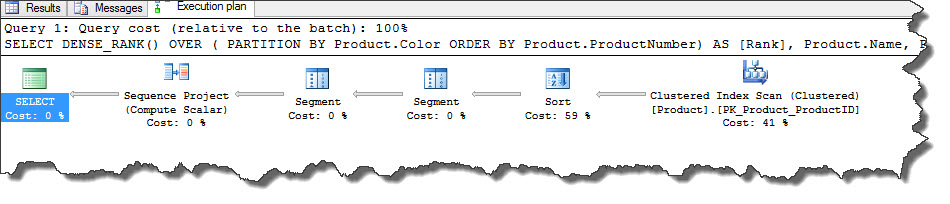
Two Segments (you can read more on segment operator here) and Sequence Project work together to produce result of the DENSE_RANK OVER PARTITON BY clause used in the query statement. The first Segment operator has a GROUP BY argument of Color column and it uses segment column labelled with [Segment1004] to specify if the current row is first row that belongs to a new group.

The second Segment operator is required because then DENSE_RANK() changes when the current value differs from previous row. In order to house this, the query plan requires a second flag and stored in the second segment column [Segment1005].

With these two segments, now Sequence Project can decide if it has to increment, rest or leave the internal value for the DENSE_RANK() function. Sequence project adds this internal value as a new column and same is reflecting in our example as [Expr1003].

That’s all for today, I’ll be back tomorrow with a new operator, till then.
Happy Learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook