Processing is an operation to keep an Analysis Services database (ASDB) up-to-date with the current data from an OLTP system or a data warehouse based on how an ASDB is designed. It is the responsibility of an administrator to manage the processing tasks on a regular basis. It may be a single step or a series of steps to populate the Analysis Services objects with data based on the type of objects and the various processing options.
Processing – Behind the scenes
Processing is an important step to keep the SQL Server Analysis Services objects alive. When the processing of objects is in progress, they can still be accessed using queries. The processing happens inside a transaction which means either the entire changes can be committed on success or rolled back on failure thus maintaining the consistency and reliability of the cube data. On success, the changes are being committed to the objects, during which the objects are temporarily unavailable for query. The queries will be queued and once committed the objects are again available for user query and processing.
Objects that are processed include Analysis Services databases, cubes, dimensions, measure groups, partitions, and data mining structures and models. We can set the processing options and settings for each object differently as per the requirement. It is very important to understand the dependency between objects while processing. For example, fully processing a dimension invalidates the underlying partitions and hence requires processing partitions as well. Thus processing the highest-level object causes the processing of all the lower level objects. Let’s understand the object hierarchy to know which objects get affected when processing an object in a particular level.
- Database
- Cube
- Dimension
- Partition
- Measure Group
- Partition
- Dimension
- Cube
Database – Processing a database processes some or all partitions, dimensions, and mining models that the database contains
Cube – A cube contains dimensions and measures which are managed using partitions. Processing a cube processes any unprocessed dimensions in the cube, and some or all partitions within the measure groups in the cube. Processing a cube creates files storing fact data and aggregations.
Dimension – Processing a dimension does not create or update calculated members and aggregations. Note that a dimension can be shared among several cubes and hence processing such a dimension marks these dependent cubes as unprocessed. Usually such dimensions and the dependent cubes are processed at the same time using batch processing settings.
Measure Group – Processing a measure group processes some or all partitions within the measure group, and any unprocessed dimensions that participate in the measure group
Partition – Partitions play an important role in managing the cube data effectively and efficiently. Partitions have to be created, processed and merged on a regular basis to enable fast query response time and high processing throughput. Processing a partition processes that partition and any unprocessed dimensions that exist in the partition. As we can process a single partition without affecting others, we can have separate partitions for current and historical data and only the partition containing the current data can be processed regularly. Also Analysis Services can process the partitions in parallel saving the processing time.
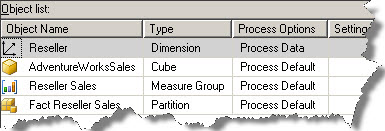
OLAP objects can be processed using SSMS, BIDS or using XMLA scripts. To process an object in SSMS, right-click on an object and select processing from the context menu. This will open the process object dialog box. Before processing an object, we can analyze the effect on related objects by clicking the Impact Analysis button in the process object dialog box. The below screenshot displays the result of Impact Analysis when the Reseller dimension is selected for Process Data option. We will be discussing more on the processing option in the next section.

Processing Options & Settings
Based on the type of object like cube, dimension, partition etc., SSAS provides different processing options to control the processing task. We can select the appropriate processing option or let Analysis Services determine the suitable processing type.
The following table describes the different processing options available in Analysis Services along with the supported object types in each option.
| Processing Option | Description |
| Objects Supported | |
| Process Default | Detects the state of an object and selects the suitable processing option to bring the unprocessed or partially processed objects to a fully processed state. |
| Cubes, Databases, Dimensions, Measure Groups, Mining Models, Mining Structures, and Partitions | |
| Process Full | Processes an Analysis Services object and all the objects that it contains. In case of an existing object Analysis Services drops all data in the object, and then processes the object. Process full is required when a structural change has been made to an object like adding, modifying or deleting an attribute hierarchy. |
| Cubes, Databases, Dimensions, Measure Groups, Mining Models, Mining Structures, and Partitions | |
| Process Incremental | Adds new fact data to the relevant measure groups and partitions. |
| Measure Groups, and Partitions | |
| Process Update | Forces a re-read of data and an update of dimension attributes. New members are added to a dimension and the data is re-read completely to update object attributes. |
| Dimensions | |
| Process Index | Creates or rebuilds indexes and aggregations for all processed partitions |
| Cubes, Dimensions, Measure Groups, and Partitions | |
| Process Data | The data is populated or removed and re-populated in the object without building indexes or aggregations. |
| Dimensions, Cubes, Measure Groups, and Partitions | |
| Unprocess | Drops the data in the object specified and any lower-level constituent objects. The data is only dropped and not repopulated. |
| Cubes, Databases, Dimensions, Measure Groups, Mining Models, Mining Structures, and Partitions | |
| Process Structure | Create only cube definitions for previously processed cubes. For unprocessed cubes, it will process all the cube’s dimensions, if required. |
| Cubes and Mining Structures | |
| Process Clear Structure | Removes all training data from a mining structure. |
| Mining Structures | |
Processing settings let you control the objects that are processed, and the methods that are used to process those objects.
| Processing Settings | Description |
| Parallel | Used for batch processing to improve the processing speed. It allows setting the maximum number of parallel tasks otherwise the server decides the optimal distribution. The processing tasks will run in parallel but inside a single transaction. |
| Sequential (Transaction Mode) | Applies to the processing job to control the execution behavior. The options available are,
|
| Writeback Table Option | Controls how writeback tables are handled during processing. (This is out of the scope of this course) |
| Process Affected Objects | When selected, processes all the dependent objects in relation to the object selected for processing. |
| Dimension Key Errors | Determines the action taken by Analysis Services when errors occur during processing |
Implementing Batch Processing
Batch processing allows SSAS objects to be processed in batches. The object dependency in processing which we have seen in the earlier module can be taken care of using batch processing. This option allows selecting a set of dependent objects to be processed and also control the order in which the objects should be processed. A batch can run as a single transaction or a series of independent jobs.
Refer to the above screenshot of Impact Analysis in the earlier section which shows that the Fact Reseller Sales partition is marked as Unprocessed when a Reseller dimension is selected for Process Data or Process Full option. Hence the user cannot browse the Reseller Sales measure group which is depending on this partition. To handle this issue, select the entire dependent object so as to process all the objects in a batch.
Click on the Change Settings button on the Process Dimension dialog box which opens the Change Settings dialog box. This provides the options to apply transactional processing. To do the batch processing, we can also select a checkbox for Process affected objects as shown in the following figure.

The batch processing is also available in the BIDS studio using solution explorer. Remember to deploy the objects before processing. Alternatively we can use XMLA scripts to implement batch processing. The scripts can be scheduled using SQL Server Agent jobs to automate batch processing.
Using SSIS for processing
SQL Server Integration Services (SSIS) provides an option to process Analysis Services objects using the Analysis Services processing task. This task also supports batch processing. When SSIS is used for Extract, Transform and Load (ETL) process, typically Analysis Services processing tasks is included at the end to refresh the cube with the latest data available in the data warehouse.

Regards
Amit Karkhanis
Like us on FaceBook | Follow us on Twitter
Join the fastest growing SQL Server group on FaceBook
How can we use Control-M to process cubes/database. please advise.
excellent snapshots with clear presentation on SQL Server: SSAS – Understanding and configuring Processing Settings……..