Hello Folks,
If you might be searching all around for the query to transform the rows of data to columns and columns of data back to the rows, then you don’t have to worry at all because I am going to deal with these queries in a moment 🙂
What is CrossTab Query?
The Cross-tabulation, or Crosstab, query pivots the second GROUP BY column (or dimension) values counterclockwise 90 degrees and turns it into the crosstab columns.
Although the columnar GROUP BY query can have multiple aggregate functions, a crosstab query has difficulty displaying more than a single measure.
The following are the methods to transform the row data into different column attributes-
- Pivot Method
- Case Expression Method
- Dynamic Crosstab Queries
The method which is being use to transform the column attributes back to the row is by using “Unpivot Method”. We will deal with each one of them separately:
PIVOT Method:
- Microsoft have the introduced this keyword with the release of SQL Server 2005, which is being used for coding crosstab queries.
- The pivot method deviates from the normal logical query flow by performing the aggregate GROUP BY function and generating the crosstab results as a data source within the FROM clause.
- If you think of PIVOT as a table-valued function that’s used as a data source, then it accepts two parameters. The first parameter is the aggregate function for the crosstab’s values. The second measure parameter lists the pivoted columns.
- This method will be more clear to you, of you carefully see this example:
First, see the table that we are using in the query;
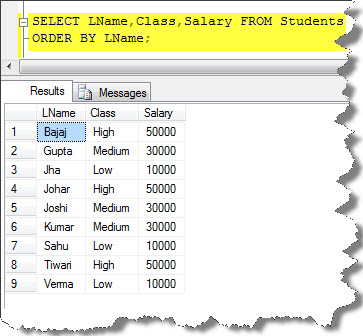
So, as per the definition of Cross-Tab query, I will pivot the second column values counterclockwise (90 degrees) and turns it into the crosstab columns.
Here, the aggregate function sums the “Salary” column, and the pivoted columns are the “Class”. Because PIVOT is part of the FROM clause, the data set needs a named range or table alias as “pt”. So you can see the query as:
SELECT LName,High,Low,Medium FROM (SELECT LName,Class,Salary From Students) sq PIVOT (SUM(Salary) FOR Class IN (High, Low, Medium) ) AS pt
The result-set can be seen as:
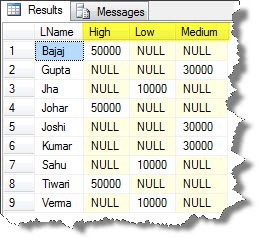
So, you can observe that the “Class” column is being transformed to different attribute classes. And the “LName” field which does not match the “Class” attribute is being replaced with the NULL.
Well this was all about the PIVOT method, and is enough for the PART 1.
In the next article post I will be writing about Case Expression Method, Dynamic Crosstab queries and Unpivot method.
So be in touch!
Hope you got it understood well 🙂
And also comments on this!!
Regards
Piyush Bajaj
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook
I found this article very helpful.
Thanks Piyush.
Do you have any idea how I could create a crosstab with labels that span more than one column?
Group One Group Two
A B C A B C
SomeRecord (values here…across six columns)
Very Good !
Your Code Is UseFull
Dear Friend,
I have a small QUery in SQL
I have huge data around more than 12 lac. its not possible to make pivot in Excel due to limitation.
Can i have query to create pivot in SQL and then paste it on Excel.
and it will autorefresh.
I need average
Hi,
I have a table as below
Name jan feb mar
F 64 65 74
C 25 13 38
I wanted to make the above table as follows
Name Month value
F jan 64
F feb 65
F mar 74
C jan 25
C feb 13
C mar 38
please help me on the same…
Hi Friends,
I have a table
Name jan feb mar
F 64 65 74
C 25 13 38
I want to convert the same into
Name Month value
F jan 64
F feb 65
F mar 74
C jan 25
C feb 13
C mar 38
can you please help me on the same
hi i have tow table
Create Table – Member
Column In Table
MemberId unique – auto increment
MeberCode varchar
MemberName varchar
JoinigDate date
Salary numeric
and
Create Table -Attendance
Column In Table
Id unique – auto increment
MemberId int
Attendance date date & Time
and i want a store procedure that show report like
Member Code Member Name Month 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
xyz xyz april P P P WO P P P P P P WO P A P P P P WO P A P P P P W