Hello Folks,
You might have seen in my previous article post “Building CrossTab Queries – PART 2”, which deals with functioning of the PIVOT method, Case Expression Method and Dynamic Crosstab Queries. If you want to see it, you can browse the link from here;
Well this article is being based upon UNPIVOT method.
UNPIVOT Method:
- It can also be seen as inverse of a crosstab query, which is extremely useful for normalizing denormalized data.
- It does this by twisting the data back to a normalized list, i.e., clockwise 90 degree.
- The UNPIVOT can only normalized the data supplied to it, so if the pivoted data is an aggregate summary, that’s all will be normalized, and the details won’t appear.
- This example should make you understand about the UNPIVOT are:
First, see the base table that we are using in the query;
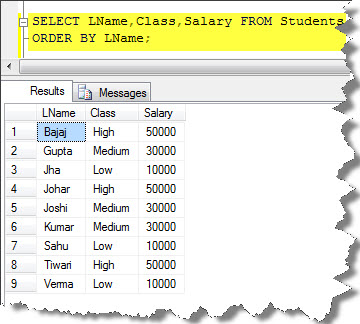
Now, drop the table if it exists with the same name:
IF OBJECT_ID('PivotTable') IS NOT NULL
DROP TABLE PivotTable
GO
What we will do is that, first we show how the PivotTable looks and then with the help of UNPIVOT method, we will bring the table back to the Normal form, i.e., first changing from rows data to different column attributes (PIVOT) and then again bringing back all the column attributes back to the data rows (UNPIVOT).
So, now using the PIVOT method:
SELECT LName,High,Low,Medium
INTO PivotTable
FROM ( SELECT LName,High,Low,Medium
FROM (SELECT LName,Class,Salary From Students) sq
PIVOT
(SUM(Salary)
FOR Class IN (High, Low, Medium)
) AS pt
) AS Q
So you can see the data with the help of the query:
SELECT * FROM PivotTable
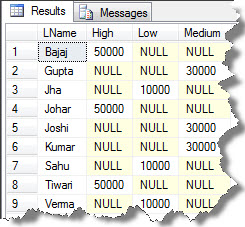
Now, we will bring back the column attributes back to the row with the query:
SELECT LName,Class,Salary FROM PivotTable
UNPIVOT
(Salary
FOR Class IN (High, Low, Medium)
) AS sq
So you can see the result set as:
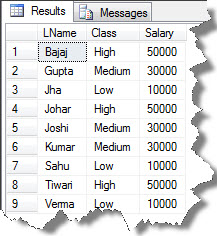
With this I come to an end of my article sequel on “Building CrossTab Queries”.
Hope you understand all the stuff’s which I presented here, and should help you to implement this idea in your projects.
Hope you got it understood well 🙂
And also comments on this!!
Regards
Piyush Bajaj
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook
When I do the same I donot get the original result. while performing UNPIVOT I get even those rows that have nulls in them.
Are you sure that you are performing the UNPIVOT in a right manner?
select OBJECT_ID, TYPE, type_desc from sys.indexes
———————————————————————-
IF OBJECT_ID(‘PivotTable’) IS NOT NULL
DROP TABLE PivotTable
GO
select [OBJECT_ID], [CLUSTERED], [NONCLUSTERED], [HEAP]
INTO PivotTable from
(select [OBJECT_ID], type_desc , [TYPE] from sys.indexes) pt
PIVOT
(count(TYPE)
for
type_desc in ([CLUSTERED], [NONCLUSTERED] , [HEAP])
) as sq
Select * from PivotTable
———————————————————————–
select [OBJECT_ID], [type_desc], [TYPE] from PivotTable
UNPIVOT
([TYPE] for type_desc in ([CLUSTERED], [NONCLUSTERED], [HEAP])
) AS sq
————————————————————————————-
Above queries are being fired. Please help if I am missing something or if I am wrong anywhere.
Thanks
Hi,
I’m creating editable crosstab table in Access. I have problem to create a table that will save edited data in the Crosstab Table. Can you explain to me how can I do that? Thanks