Hi Friends,
I hope you are finding this series useful and read my previous posts Part1, Part2, Part3 and Part4 where I covered different operators. Today I’m going to talk about two more important SQL Server Execution plan operators, let’s start right away;
Stream Aggregate and Compute Scalar
Following are MSDN extracts as it describes Stream Aggregate and Compute Scalar;
Stream Aggregate: The Stream Aggregate operator groups rows by one or more columns and then calculates one or more aggregate expressions returned by the query. The output of this operator can be referenced by later operators in the query, returned to the client, or both. The Stream Aggregate operator requires input ordered by the columns within its groups. The optimizer will use a Sort operator prior to this operator if the data is not already sorted due to a prior Sort operator or due to an ordered index seek or scan. In the SHOWPLAN_ALL statement or the graphical execution plan in SQL Server Management Studio, the columns in the GROUP BY predicate are listed in the Argument column, and the aggregate expressions are listed in the Defined Values column. Stream Aggregate is a physical operator.
Compute Scalar: The Compute Scalar operator evaluates an expression to produce a computed scalar value. This may then be returned to the user, referenced elsewhere in the query, or both. An example of both is in a filter predicate or join predicate. Compute Scalar is a logical and physical operator.
Let us look with an example, how they appear in execution plans?

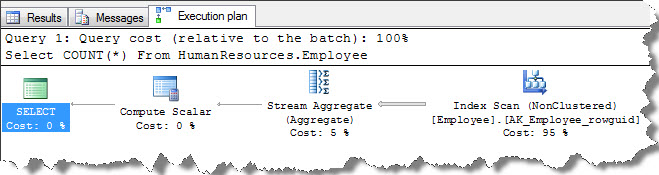
We will now decode query plan in text;
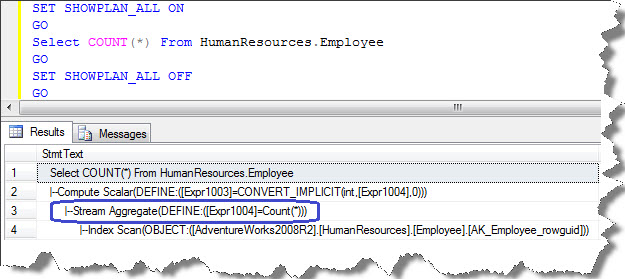
You can clearly observe that aggregation happens because of COUNT(*) operation. In addition, we could observe Compute Scalar on the plan, which is responsible for implicit conversion of COUNT(*) operation.
This is just an illustration and you may observe different behaviors on these operators based on different scenarios.
Merge Join
The Merge Join operator performs the inner join, left outer join, left semi join, left anti semi join, right outer join, right semi join, right anti semi join, and union logical operations and is a physical operator. A merge operator can be used only when both sets of rows are pre-sorted according to the join expression(s). Merge join combines the advantage of hash match and nested loops. It results in low CPU consumption and enables fast output of matched rows for further processing.
Let us join Sales.SalesOrderHeader and Sales.SalesOrderDetail;
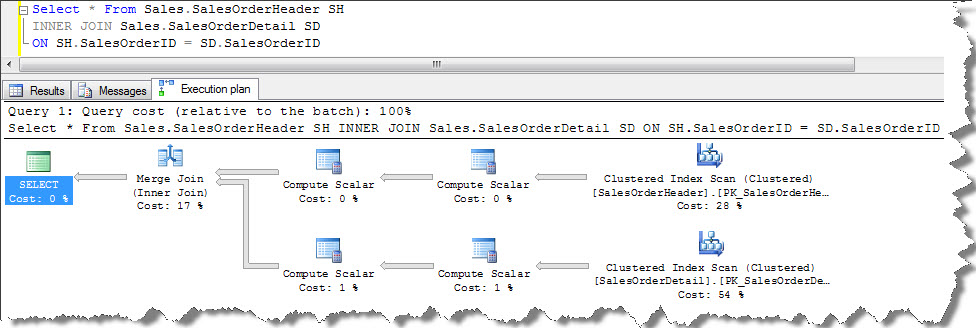
According to the execution plan, query optimizer performs a Clustered Index Scan on Sales.SalesOrderHeader and Sales.SalesOrderDetail tables. I did not specify a WHERE clause hence a scan is performed on each tables to return result-set, then all rows from both the tables are joined using Merge Join. When we look at the ToolTip of Merge Join operation (shown in screenshot below), it is observed that SalesOrderID column used to join both the tables.
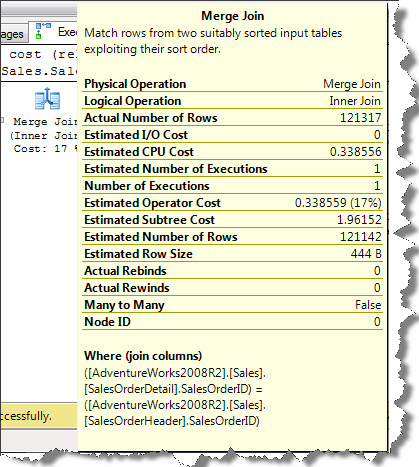
Query used for this demo joined cluster index of both the tables. As clustered index sorted in the order of clustered keys, it covers all queries and thus used to retrieve any column in the table that are specified in SELECT statement. Note, even SELECT * won’t require any additional lookups. Bear in mind, when we select all columns, both the tables needs to be loaded in memory and needs to send over network so there could be a performance overhead so better to specify the required ones. One important point to note here is; when the join columns are presorted but if the join columns are not presorted; query optimizer has the option of EITHER;
- Sorting the join columns first then performs a Merge Join
OR
- Performing a less efficient Hash Join
The query optimizer checks for all the options and then chooses the execution plan that uses the least resources.
Stopping here today; I will be back with next part soon with some more operators.
Regards
Kanchan Bhattacharyya
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook