Hi Friends,
I am writing this blog on my way back from Great Indian Developer Summit where I presented 2 sessions and received great feedback on my session. I had started the SQL Server Index Internals series sometime back and posted two blogs. You can find them here:
This is the third one in the series and today I will talk about Index Union operations.
Lets create two non-clustered indexes on SalesOrderHeader table in AdventureWorks database:
USE AdventureWorks GO CREATEINDEX idx_nc_OrderDate on sales.SalesOrderHeader(OrderDate) CREATEINDEX idx_nc_ShipDate on sales.SalesOrderHeader(ShipDate)
And execute the following query (turn on actual execution plan):
SELECT SalesOrderId FROM sales.SalesOrderHeader WHERE OrderDate BETWEEN'2002-01-01'AND'2002-01-07' OR ShipDate BETWEEN'2002-01-01'AND'2002-01-07'
After observing the above query, you will notice why I created two non-clustered indexes on OrderDate&ShipDate respectively. Now let us see the execution plan for the above query and analyze what the optimizer has done:
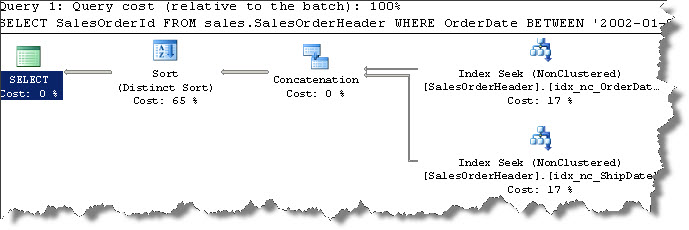
The optimizer has basically used both the indexes since we were using those columns in our query predicates. And it joins the data (concatenation operator). This kind of operation is called as Index union.
So here is a question for you; what is the purpose of Distinct Sort operator? Post your answers as comments 🙂 – And yes, I will respond to each comment (I know I have been late in responding and still some responses are pending. I will clear my back log quickly 🙂
My guess is that because you concatenate 2 results that come from 2 differents indexes involve a high potential of duplicate results of SalesOrderId that comes from these 2 indexes. SQL needs to remove those duplicates to conform to expected results of the query (Only 1 table is used in the query that sould not produce duplicates if SalesOrderId is unique). The most effective way to eliminate duplicates is sorting them and removing multiple consecutive identical results.
My Question is the following:
– What happens if SalesOrderId is not Unique in the table? How SQL Server can identify duplicates that comes from the scan of 2 indexes from the real duplicates in the table (that must be returned).
– The execution plan will probably looks different, if you could provide an example and explain the new one it could be great
Thanks for this explanation, learning a little thing each day make better DBA.
Hi Amit
How can i tune or create index on below query if employee table is huge.
select * from employee where last_name like ‘%A’
It says DISTINCT sort. After merging data selected from 2 unrelated indexes some of which can refer to the same records, it needs to pick distinct records only.