Hi Friends,
Here is a query and I want to create the right indexes for it. Let us do things step by step: (I am using AdventureWorks2008 for this)
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
go
In the above query we are doing a SUM on SubTotal and grouping by CustomerID – the business requires total sales for all the customers.
When we run the above query, we get the following execution plan (provided you have not done any changes to the default indexes on SalesOrderHeader table)

As you can see it does a clustered index scan which is fine as it needs to read all the records on the pages. But we also see that there is a Hash Match and the moment we see Hash operations, we can try to improve upon it.
Furthermore, my business tells me that they need the reported sorted by customerID. So I modify the query as follows and run it.
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
go
When I observe the execution plan, this is what I get.

And rightly so, the optimizer adds a Sort operator. Now there is certainly some room for improvement here – look at the 56% cost of the Sort Operator and we are dealing with 32000 rows approx..
When I run the missing index DMV, it does not suggest me anything at all. You can try it as well to see if you get any recommendations:
select d.*
, s.avg_total_user_cost
, s.avg_user_impact
, s.last_user_seek
,s.unique_compiles
from sys.dm_db_missing_index_group_stats s
,sys.dm_db_missing_index_groups g
,sys.dm_db_missing_index_details d
where s.group_handle = g.index_group_handle
and d.index_handle = g.index_handle
order by s.avg_user_impact desc
go
Coming back to our example, we shall try to improve the performance of the query by creating the right indexes that cover the query.
Let us try the first option:
CREATE INDEX Option1 ON Sales.SalesOrderHeader(SubTotal, CustomerID) go
This index creates a covering index as it includes SubTotal & CustomerID and covers the query. But notice the order of columns. Let us run the query and see if the optimizer picks up this index or not.
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
go

Yes, the index gets picked up. But is there a performance improvement? Run both the queries as a batch and observe their relative cost:
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
go
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH with (index(0))
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
OPTION (MAXDOP 1)
go
Select both the queries in your query window and press F5. I run the first one as before where the optimizer chooses the best option. I run the second one with the hint to use the clustered index, mimicking the previous behavior. Now, observe their relative cost in the execution plan.
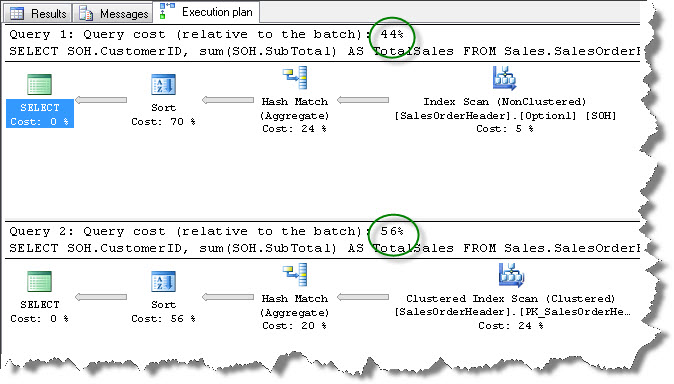
You will observe that there is slight performance improvement. 44% vs 56%.
Is there any scope of further improvement? Yes there is, since we have still not got rid of Sort and Hash operator out there. This improvement is just because we are using a covering index. But this index does not have the columns in the right order (remember the order of the columns when we created the index)
Let us create another index:
CREATE INDEX Option2 ON Sales.SalesOrderHeader(CustomerID, SubTotal) go
This time I change the order of columns ensuring that my index is sorted on CustomerID.
Run the query to see if the optimizer picks up this index. Remember, we have not dropped the other indexes.
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
go
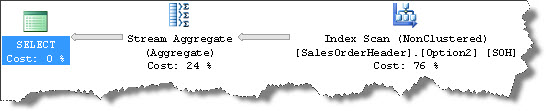
Yes, the optimizer picks this up. And most interestingly, it changes the HASH operator to Stream Aggregate and the Sort operator is also gone. Why? Simply because now the data is in sorted on customerID and Stream Aggregate needs that and gets that. But is there any performance improvement?
Let us run this query and the previous query in a batch and observe the relative cost.
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
go
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales
FROM Sales.SalesOrderHeader AS SOH with (index(option1))
GROUP BY SOH.CustomerID
ORDER BY SOH.CustomerID
OPTION (MAXDOP 1)
go
Just like before I run the first one (let SQL Server decide the best approach) and the second one with a hint to use Option1. Select both the queries in SSMS and press F5.
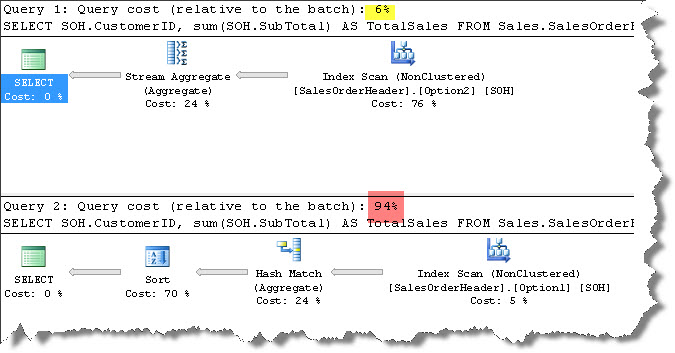
Observe the performance improvement. 6% vs 94%.
Having the right indexes is very critical to get the right performance from your queries. I would also like to point out that covering indexes are good but they are covering with respect to a particular query. Creating too many covering indexes to cover your queries is also not the right approach. You need to strike a fine balance here. We could have also created Option2 with included columns (putting SubTotal in include list) which is also the right approach but in this case we would have hardly got any performance improvement given the size of data and also that our index keys are very small. But you can certainly try that option as well – don’t rule that out.
Hope you enjoyed reading this article.
Do post your comments and spread the word.
Good explanation!
Great article. Would you get similar performance gains from a more generally useful index just on the CustomerID (not including SubTotal as you did)?
Amit let me try to explain.
The whole idea of the above example was to change the Hash aggregation to a much light weight stream aggregation.By adding the index what exactly we are doing is that we are sorting the records in the index based on the clustered key because the optimiser is going for a clustered index scan instead of a table scan.Try droping the clustered index from the table and run the query.You will surprised to see the results.It will actually use a stream aggregrate instead of a hash aggregate but with a sort operation.
Since there is no sort order defined for the columns in the query the optimiser will go for a hash operation but if an index is added the optimiser can see that the columns in the query are already sorted in the index which is the basic requirement for a stream aggregate it goes for a stream operation.The best we can do is streamline these 2 columns with the already physically sorted clustered key i.e SalesOrderId.
Now for your original question.If you just add an index only on the column CustomerId the aggregation which is happening on the column SubTotal will not be covered by the index and the optimiser will still use a hash operation to compute the sum value for the subtotal column.
Also it is not necessary for one to use a covering index you can even go for a composite index on this two columns.Beware if the no of rows and groups are less and are static but fairly volatile then maintaiing the index will be a much overhead than the disadvantages of the hash operation.
Sachin,
We will be glad to see you explaing you own wirtings 🙂 – you have just spend some of your valuable time in explaining whatever I have already explained – nonetheless, I welcome the explanation again 🙂
“The whole idea of the above example was to change the Hash aggregation to a much light weight stream aggregation” – read my 4th line where I say “But we also see that there is a Hash Match and the moment we see Hash operations, we can try to improve upon it”
“By adding the index what exactly we are doing is that we are sorting the records in the index based on the clustered key because the optimiser is going for a clustered index scan instead of a table scan. .You will surprised to see the results.It will actually use a stream aggregrate instead of a hash aggregate but with a sort operation” – yes, so what’s the point, I know it !
“Since there is no sort order defined for the columns in the query the optimiser will go for a hash operation but if an index is added the optimiser can see that the columns in the query are already sorted in the index which is the basic requirement for a stream aggregate it goes for a stream operation.The best we can do is streamline these 2 columns with the already physically sorted clustered key i.e SalesOrderId.” – again, whats the point, I know it !! I mean, the optimizer will do whats right here, I did not understand the context..
“Now for your original question.If you just add an index only on the column CustomerId the aggregation which is happening on the column SubTotal will not be covered by the index and the optimiser will still use a hash operation to compute the sum value for the subtotal column.” – I dont know which original question you are referring to but there could be millions of combimations that way !! cant talk about all of them in one post !
“Also it is not necessary for one to use a covering index you can even go for a composite index on this two columns.”—I think you are confused between covering index and composite index. What have I created in may last leg, Option2 – is it covering index or composite index? 🙂
“Beware if the no of rows and groups are less and are static but fairly volatile then maintaiing the index will be a much overhead than the disadvantages of the hash operation.” – Nothing to beware of, there could be millions of scenarios, and there is a way to deal with all of them !!
Shucks!!!!! Amit actually my answers were directed to the question asked by rsl922.Thats the reason I said “Amit let me try to explain…” which was directed to rsl922
Sachin, I apololize to you for this and take my comments back. Sorry my friend ! – I misunderstood so badly !!
No wonder why I was so surprised and was wondering – “Whats wrong with Sachin????” 😀 – I am just laughing out loudly !!!
And thanks much for responding to rsl922
THANKS FOR YOUR CONTRIBUTION !!!!
No probs Amit..Thank god you still think me as your friend 🙂
Why do you need to add the SubTotal column in the index. can you just have it as include. Can you have the index:
CREATE INDEX Option2
ON Sales.SalesOrderHeader(CustomerID)
INCLUDE (SubTotal);
@SQLServerguy,
Yes you can do that. Please read my reply to the question posted above by rsl922.
Hello! Thanks for the tutorial, but I still have some questions:
Let’s say you have a datetime column named SaleDate and you also want to get the most recent sale date of each costumer, ordered by the aggregate function on SaleDate. You’d do something like this:
SELECT SOH.CustomerID,
sum(SOH.SubTotal) AS TotalSales,
max(SOH.SaleDate) AS MostRecentSaleDate
FROM Sales.SalesOrderHeader AS SOH
GROUP BY SOH.CustomerID
ORDER BY MostRecentSaleDate
And now, what about the index? How can we best optimize this query?