Friends,
As of now we covered SQL Server Execution Plan Clustered Index Scan on Part 1, Clustered Index Seek and Non-clustered Index Seek on Part 2 and Key LookUp and Table Scan on Part 3. Today, as part of this post we will cover RID LookUp and Hash Match (Join) operators.
RID LookUp
Let me modify the query that was used for Table Scan by introducing a WHERE clause;

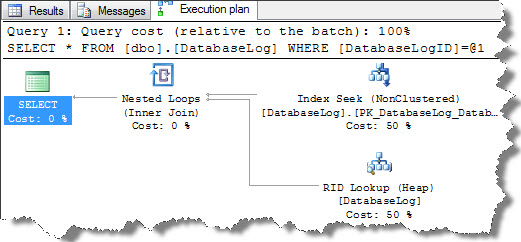
Ok, we can observe Nested Loop, then Index Seek followed by RID LookUp on execution plan. To retrieve result of this query, query optimizer first performed an Index Seek on PK_DatabaseLog_DatabaseLogID as this was mentioned on WHERE clause (see below) however all required details weren’t part of index. Question is obvious, how do we conclude this? Answer is simple, if you look at the ToolTip test carefully for Index Seek it shows ‘Bmk1000’ in output list which says that, Index Seek is part of query plan that have bookmark lookup.
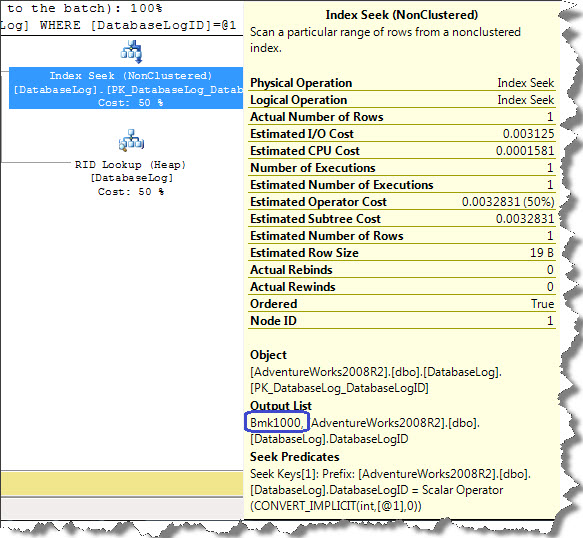
Next we see RID Lookup (see below image), which is a kind of bookmark lookup that is performed on a Heap table (table with no clustered index). It uses a row identifier to retrieve the rows since the table doesn’t have a clustered index. This is an additional I/O overhead which are then combined by Nested Loop.
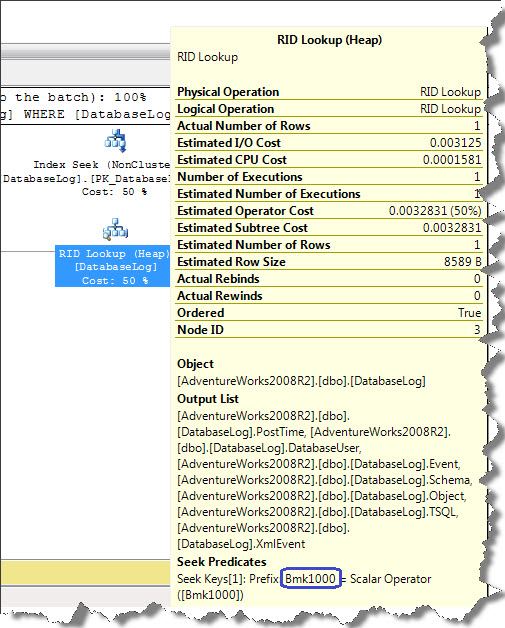
If you look at Seek Predicates section on ToolTip, it shows Bmk1000’ again which tells us, a bookmark lookup was used in query plan. In our example, only one row is returned which may not affect anything but given a scenarios, where you have number of rows that are being looked up it is worth considering either to re-write the query or to introduce appropriate indexing.
Hash Match (Join)
Hash join is formed using two processes i.e. Build and Probe. Optimizer chooses the smaller process as build input. It creates a Build hash table by computing a hash value for each row from build input after that, from the Probe input it creates the has value for applicable rows using same hash function which looks in build has table while matching. There are three types of hash join i.e. In-Memory Hash Join, Grace Hash Join and Recursive Hash Join which are explained on MSDN. Let us try hash join using a simple query;

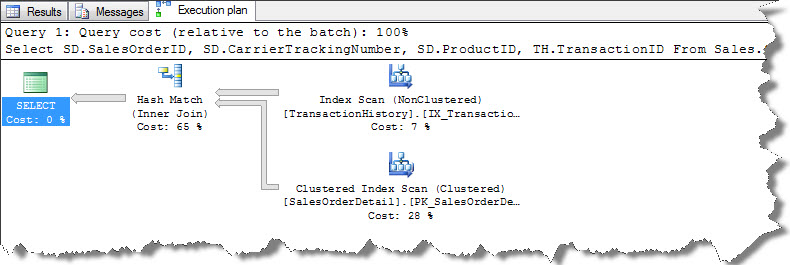
You can observe Hash Match Join in execution plan then Non-Clustered Index Scan and Clustered Index Scan. We are going to focus on Hash Match for now. Let us check how ToolTip looks like;
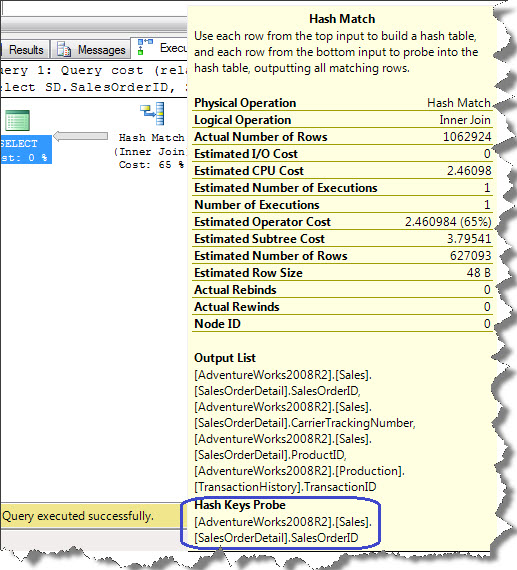
In our case Sales.SalesOrderDetail table is used as Probe input because it is having more records as compared to Production.TransactionHistory table which is used a Build input.
I hope this explains RID LookUp and Hash Match Joins, stay tuned for more on this series.
Regards
Kanchan Bhattacharyya
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook