Hello,
As a DBAs we get lot of request to tune queries and we normally suggest to create Index or Update Statistics but tuning also needs rewriting of actual query and the normally performance Issue is caused by lot of Nested SQL Server Subquery.
So here is a demo what I want to write, soon ill update some more tips related to rewrite your actual query to improve performance.
This is the demo script which I need to tune as a performance tuning DBA
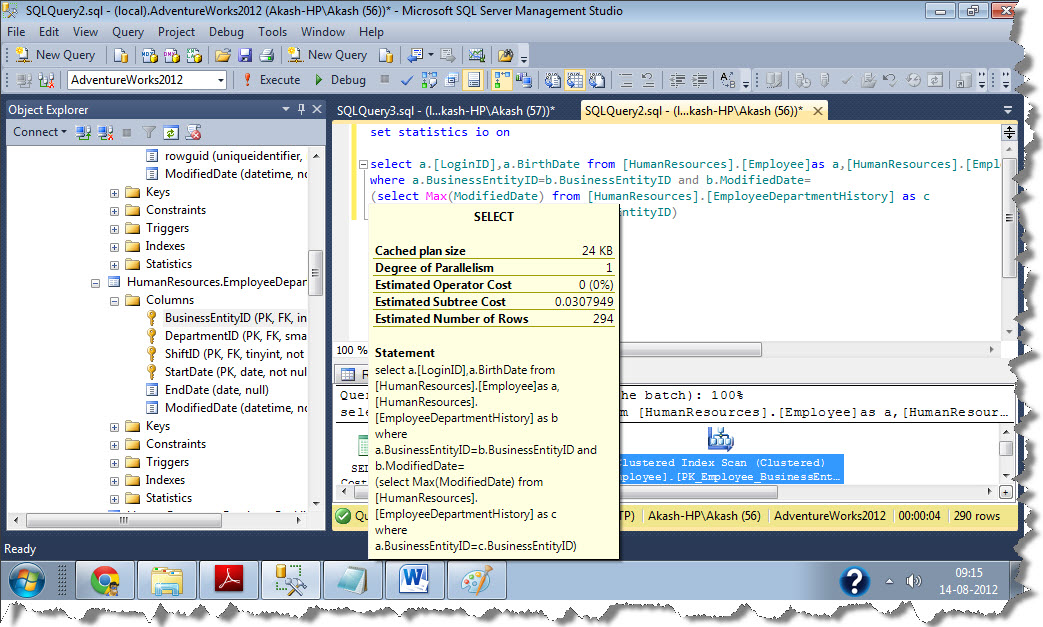
set statistics io on select a.[LoginID],a.BirthDate from [HumanResources].[Employee]as a,[HumanResources].[EmployeeDepartmentHistory] as b where a.BusinessEntityID=b.BusinessEntityID and b.ModifiedDate= (select Max(ModifiedDate) from [HumanResources].[EmployeeDepartmentHistory] as c where a.BusinessEntityID=c.BusinessEntityID)
If you will look into below screenshot

Scan count for EmployeeDepartmentHistory is 2,although Logical reads are 8 only as it is very small table .Scanning table two times can impact your performance when table would be of the size of 400-500 Gb
Scan count is 2 because above mentioned table is getting used 2 times in the query, 1st in outer query and then in sub query
We can use Concept of Analytical Function here which will reduce the scan count to 1

I have reduced scan count to 1 but as you can see Worktable which is temp table actually got created so it increased number of logical reads so it would be useful when you will have tables of large size ,in this scenario also I am comparing cost of above two query. I will inform you about avoiding usage of temp table in my future blogs so here I will not focus on Worktable .
Cost for first Query
Cost for 2nd query
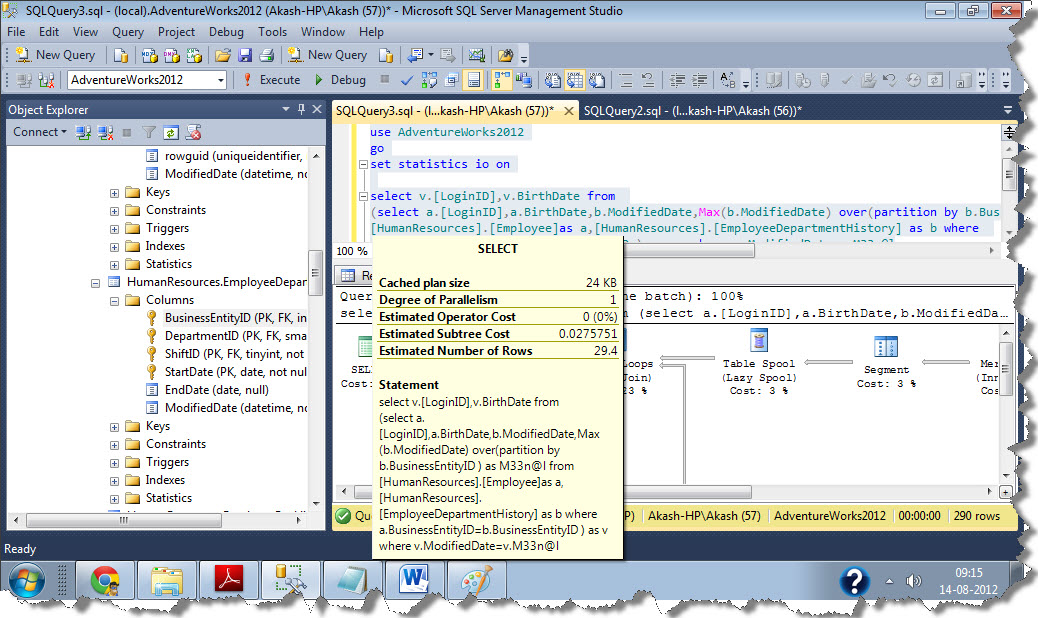
You would be surprised to see even I have more logical reads in my 2nd query still cost is less, because cost is mainly dependent on Physical IO operations or the data present in Physical disk, once you have fetched data from disk it would be easy for Query optimizer or relational Engine to manipulate is as required on memory, that’s why we prefer hash and Merge algorithm for joining two tables instead of nested loops
Ill update more tuning tips in my next blog, till then keep reading
Regards
Akash Gautam
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook
Hey Akash,
Nice blog. I had a question here :
The physical read, as you mentioned influences the cost, for the first time the query hits SQL SERVER, assuming the cache doesn’t get cleared out, the subsequent hits wil read data from the memory.
Considering the example above, you can clearly see that the physical reads are zero(0) indicating that the data is already present in the cache and the SQL SERVER need not go back to the files to fetch the data.
So I believe we should concentrate on reducing the logical reads instead of the physical ones. This is in my opinion. Is it different in your line of thinking?
Whenever query hits first on a database parsing ,optimization,code generation and execution occurs,to avoid parsing and optimization phase SQL Server stores SQL Server query plan in plan cache.We can retrieve plan by querying sys.dm_exec_cached_plans,if you will see the XML plan,it will tell you the estimated subtree cost,now takes its text from dm_exec_query_text and run the same query including actual execution plan.If statistics of columns has not been changed drastically the estimated cost of the plan present in cache and the actual execution plan will remain same.It means it is using plan present in Plan cache, if stats has been changed by huge amount ,it will create a new plan.
What i want to say is the cost which is coming here is the first time query was compiled so it depends on physical reads and not much on logical reads.hope you understand
Akash,
Thanks for the reply. If I understand your explanation properly, each time a query is executed, the execution plan that the optimizer uses considers that the data is read from the disk and not from memory?
Or am I not understanding the point here?
-Thanks in advance,
Ananthram
Yes
Reading data from Memory is very fast,you can check buffer cache hit ratio,or L1,L2,L3 cache.Cost of query depends on number of free pages present in Memory(Free Memory available) which will directly influence your Logical reads.
Logically, Cost should be independent on the type of resources present in your server ,If I am accessing data from SAN and then from SSD,duration of the query would be different in both the cases,but cost of query will remain same,same goes whether you have AMD processor or INTEL